What I Learn From AI this Week-5
圖靈獎、Yann LeCun、AI Blog

作品
AI新聞訂閱
目前有多人訂閱產業/投資高手訪談,川普政策新聞也有人表示有興趣,也可以有興趣的一起來集資製作(因為採用了新的AI模式,成本結構大幅降低,如果有興趣歡迎填寫表單詢問,價格不是網站上的價格,我猜可能是一個月20元)AI Blog
目前已經包含Buffett, Munger, Jeff Bezos, 歷年圖靈獎演講。

文章
圖靈獎演講(1966-2000)
作為外行人的我,最近開始一年年讀圖靈獎的演講,嘗試從圖靈獎的歷年得主中,摸索出人類在電腦科學、AI的發展途徑。
目前我看到2000年,總結來說,1966-1975年之前,大多數圖靈獎都在談論什麼是電腦科學,軟體程式碼該如何優化,中間似乎還經歷過一次軟體的斷層事件,因為當時軟體程式碼是採用最初的馮紐曼架構(Von Neumann architecture),並沒有辦法支援大規模的程式部署。
1975-1995年年除了既有的演算法優化之外,大家開始大量討論複雜性、資料庫和大規模系統的可能。
中間有幾篇有趣的論文,我分別羅列如下
1. 1967年ACM圖靈演講:電腦的今昔
這篇是第一篇圖靈獎演講,他談到電腦從圖靈機到實現的歷史,算是一篇歷史整理
2. 1971年ACM圖靈演講:Generality in Artificial Intelligence
這是第一篇開始談論人工智慧可能性的演講,當時的人工智慧和現在比起來,更像是某種搜尋系統。
3. 1975年ACM圖靈演講:電腦科學作為經驗探究:符號與搜尋
1975這篇圖靈獎算是把人工智慧的架構講的蠻清楚的一篇,他提到每個學科領域都可以約化到一個最小單位作為基礎,來討論各種現象,例如生物學從細胞開始,板塊構造從地球的數十個巨大的板塊開始,疾病從細菌開始等等。電腦科學則從符號開始。
裡面引用《蘇格拉底美諾篇》讓我印象深刻,在此引用如下
美諾:蘇格拉底,你如何探究你所不知道的事物呢?你會提出什麼作為探究的主題?如果你找到了你想要的東西,你又如何知道這正是你所不知道的東西呢?為了解決這個謎題,柏拉圖發明了他著名的回憶理論:當你以為自己在發現或學習某物時,實際上只是在回憶前世已經知道的事物。
如果你覺得這種解釋荒謬,今天有一種更簡單的解釋,基於我們對符號系統的理解。其近似陳述是:陳述一個問題是指定 (1) 一類符號結構的測試(問題的解),和 (2) 一個符號結構的生成器(潛在的解)。解決一個問題是利用 (2) 生成一個滿足 (1) 測試的結構。
如果我們知道我們想要做什麼(測試),並且我們不立即知道如何做(我們的生成器不能立即生成滿足測試的符號結構),我們就有一個問題。一個符號系統可以陳述和解決問題(有時)因為它可以生成和測試。
他也提到,在人工智能研究的頭十年左右,問題解決的研究幾乎等同於搜尋過程的研究。4. 1986年ACM圖靈演講:電腦科學:一門學科的興起
這也是一篇歷史回顧的演講,裡面很有趣的提到,原來程式語言是來自於神經生理學還有語言學。
1943 年,在神經生理學領域工作的 McCulloch 和 Pitts 發表了一篇關於描述神經網絡中事件的邏輯演算論文。這些事件是一系列電脈衝,可以看作是零和一的字串。這篇論文提供了一種表示法來描述這些零和一的字串如何在神經元中組合產生新的零和一字串。這種表示法後來發展成為用於描述字串集合的正規表達式語言。
Chomsky 是一位語言學家,一直在研究自然語言的語法。在他的工作中,他發展了上下文無關文法的概念。大約在同一時間,兩位電腦科學家 Backus 和 Naur 正試圖開發用於描述程式語言的形式化方法。1960 年之前,程式語言通常通過冗長且往往不完整的口頭描述來定義。各種語言實現中的不一致性常常使得在系統之間轉移軟體變得困難。Backus 和 Naur 開發了一種形式化表示法來描述各種程式語言的語法。令人驚訝的是,他們的表示法與 Chomsky 開發的上下文無關文法是等價的。
5. 1990年ACM圖靈演講:論建造會失敗的系統
談論複雜學的演講非常多,這一篇最引起我關注,他提到建構一個宏偉的複雜系統在當時的狀況下必然會面臨失敗,但是人們往往會追求這樣的計劃。例如說戰爭和交通系統。
裡面總結道:
我們似乎無法把雄心勃勃的系統做對的一個關鍵原因是變革。電腦領域沉醉於變革之中。我們看到了四十年間的飛速增長,而且這種增長似乎仍在持續。這個領域尚未成熟,但已經直接或間接佔國民生產總值的很大一部分。更重要的是,電腦革命——這第二次工業革命——已經改變了我們的生活方式,並催生了無數新的應用領域。而所有這些變革和增長不僅改變了我們生活的世界,還提高了我們的期望,在航空公司預訂、銀行業務、信用卡和空中交通管制等不同領域催生了越來越雄心勃勃的系統。電腦產業令人難以置信的增長背後,當然是數位邏輯原始性能同樣令人咋舌的變化。
今天,有跡象表明電腦科學正在轉向應用領域。隨著它將其模型、工具和技術貢獻給這些新領域,這些新領域反過來也將貢獻新的思想和方法論,極大地豐富和擴展電腦科學的範疇。潛在地,我們正處於科學新一輪增長浪潮的門檻上。然而,有兩個領域阻礙了我們跨過這個門檻。
6. 1994年ACM圖靈演講:計算複雜性與電腦科學的本質
這次演講總結了複雜性在電腦科學的歷史,摘要如下:
我們非常喜歡 Turing 1936 年的論文 ,並對不可判定性結果和基本遞歸函數論的優雅、清晰和簡潔性印象深刻。Turing 的工作為我們後續的工作提供了必要的定義明確的抽象計算機模型。
我個人對 Shannon 的通信理論 印象深刻。Shannon 的理論以 channel capacity 和信息源的 entropy 為依據,對在噪聲信道上能「可靠地」傳輸多少信息給出了精確的定量定律。
Shannon 給出了一個信息定量定律的美麗例子,信息本質上不受物理定律的直接約束。這引發了一個問題:是否存在精確的定量定律來管理抽象的計算過程,這同樣不受物理定律的直接約束。是否能有定量定律來確定對於每個問題,解決它需要多少計算努力(工作),以及如何衡量和確定它?
這些以及其他方面的考慮,促使我們堅信,必然存在管理信息和計算行為的定量定律。
電腦科學的定義性特徵之一是其處理現象在尺度上的巨大差異。從電腦中程序和數據的個別 bit,到高度複雜的機器、其操作系統以及描述問題的各種語言對這些信息每秒數十億次的操作,尺度跨越了許多數量級。
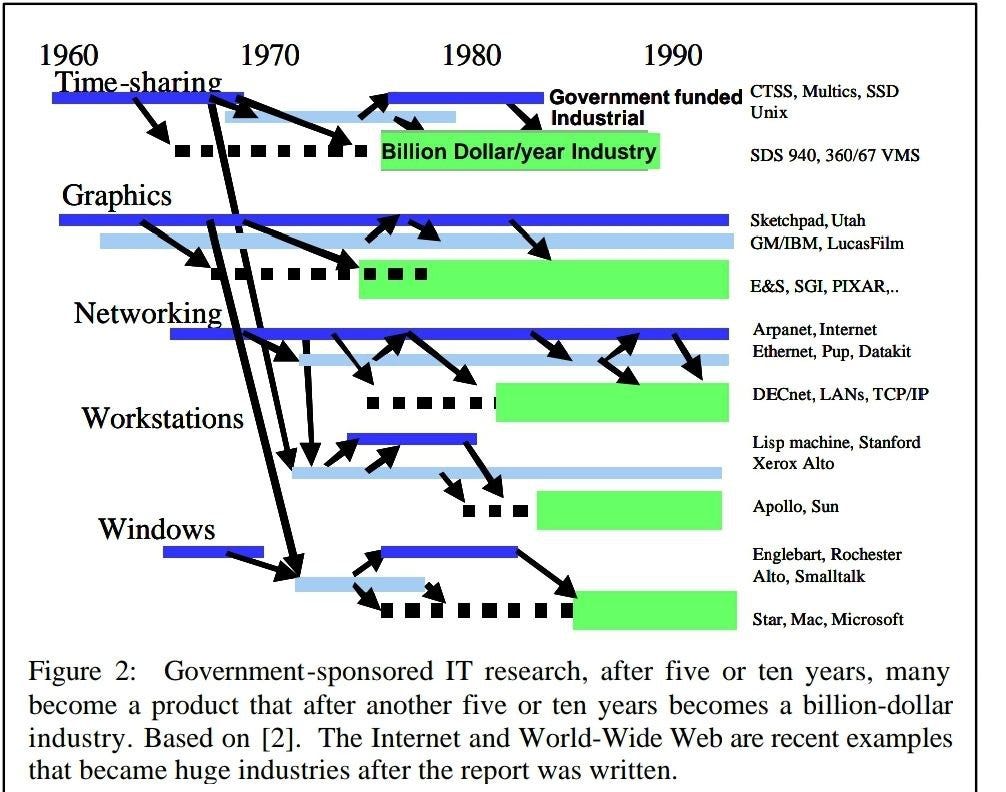
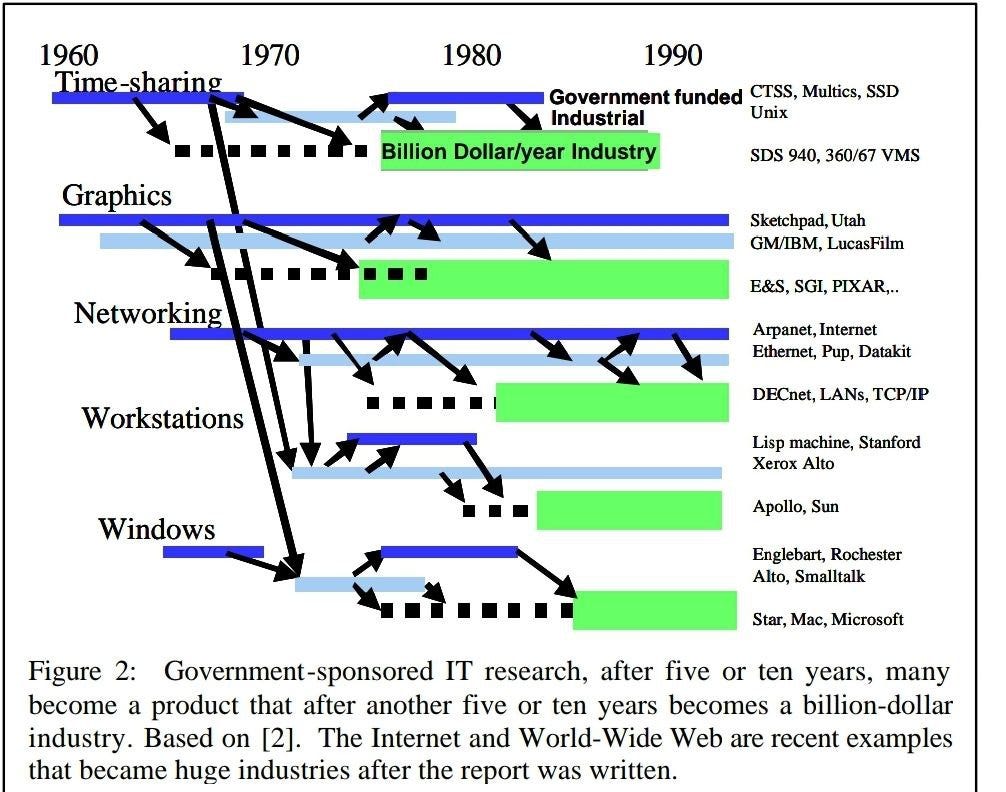
7. 1998年ACM圖靈演講:下一步是什麼?十二項資訊科技研究目標
這篇文章是第一篇我看到他總結電腦從科學到產業的過程,他當時看到科學研究到產業應用大概會花十年的時間,他認為思考資訊科技革命的一種方式是將賽博(Cyber)空間視為一個新大陸——相當於 500 年前美洲的發現。並且指出基礎研究是公共財。以及AI寒冬。
裡面總結道:
政府資助的 IT 研究,在五到十年後,許多研究成果會轉化為產品,再過五到十年則成為價值十億美元的產業。基於 [2]。Internet 和 World-Wide Web 是最近的例子,它們在報告撰寫後成為巨大的產業。
研究思想通常需要十年的孕育期才能轉化為產品。由於淘金熱,這個時間差正在縮短。研究思想仍然需要時間成熟和發展,然後才能成為產品。
領先的 IT 公司 (IBM, Intel, Lucent, Hewlett Packard, Microsoft, Sun, Cisco, AOL, Amazon,...) 將其營收的 5% 到 15% 用於研發。其中約 10% 的研發不是產品開發。我估計其中的 10%(總額的 1%)是與任何近期產品無關的純粹長期研究(大部分研發中的「研」實際上是高級開發,旨在改進現有產品)。因此,我估計 IT 產業在長期研究上花費超過 5 億美元,這筆資金資助了約 2,500 名研究人員。這是一個保守估計,其他人估計數字是兩到三倍。按照這個保守的衡量標準,工業界的長期 IT 研究規模與美國大學計算機科學系的終身教職員工數量相當。大多數 IT 產業確實資助長期 IT 研究;但是,為了保持競爭力,一些公司無法做到。MCI-WorldCom 的年度報告中沒有研發項目,諮詢公司 EDS 也沒有。Dell computer 的研發預算很小。總的來說,服務公司和系統整合商的研發預算非常小。
其中一個原因是,長期研究是一種社會公益,不一定是公司的利益。AT&T 發明了晶體管、UNIX 以及 C 和 C++ 語言。Xerox 發明了 Ethernet、位圖列印、圖標介面和 WYSIWYG 編輯。其他公司如 Intel、Sun、3Com、HP、Apple 和 Microsoft 從這些研究中獲得了主要的商業利益。社會獲得了更好的產品和服務——這就是為什麼研究是公共財。
Yann LeCun:人類智慧並非通用智慧
Highlight
所以在過去七十年的 AI 歷史中,一直重複著這樣的故事:人們提出一個新的範式,然後宣稱,好了,就是這個了。這將帶領我們達到人類水平的 AI。十年內,地球上最聰明的實體將是機器。而每一次都被證明是錯誤的,因為新的範式要麼遇到了人們未曾預見的限制,要麼結果只是擅長解決某個子類別的問題,而這個問題並非通用智慧問題。
所以,一代又一代的 AI 研究人員、企業家和創始人,不斷提出這些主張,而每一次他們都錯了。 所以,我不想貶低 LLM。它們非常有用。應該對它們進行大量投資。應該對運行它們的基礎設施進行大量投資,這實際上是大部分資金的去向。不是為了訓練它們或什麼,最終是為了服務可能數十億的用戶。但是,就像所有其他電腦技術一樣,即使它不是人類水平的智慧,它也可以是有用的。 現在,如果我們想要追求人類水平的智慧,我認為我們應該這樣做。我們需要發明新技術。我們離達到那個水平還差得遠呢。我三年前寫了一篇長文,解釋了我認為未來十年 AI 研究應該走向何方。這是在全世界了解 LLM 之前。當然,我知道它,因為我們之前就在研究。但是,這個願景沒有改變。它沒有受到 LLM 成功的影響。 事情是這樣的。我們需要能夠理解物理世界的機器。我們需要能夠推理和規劃的機器。我們需要擁有持久記憶的機器。我們需要這些機器是可控和安全的,這意味著它們需要由我們給定的目標驅動。我們給它們一個任務,它們完成它,或者它們給出我們所問問題的答案,僅此而已。
我在那份文件中解釋的是,我們可能如何,以一種方式,達到那一點。它的核心是一個叫做「世界模型(world model)」的概念。 我們腦中都有世界模型。動物也有,對吧?它基本上是我們腦中的心智模型,讓我們能夠預測世界將會發生什麼。要麼是因為世界就是世界,要麼是因為我們可能採取的行動。 所以如果你能預測我們行動的後果,那麼我們可以做的是,如果我們給自己設定一個目標、一個任務去完成,我們可以使用我們的世界模型,想像一個特定的行動序列是否真的會實現那個目標。好嗎?這讓我們能夠規劃。所以規劃和推理實際上就是操縱我們的心智模型,以弄清楚一個特定的行動序列是否會完成我們為自己設定的任務。好嗎?這就是心理學家所說的「系統 2(System 2)」。一個深思熟慮的,我不想說有意識的,因為這是一個有爭議的詞,但是一個深思熟慮的思考如何完成任務的過程,基本上是這樣。
事實上,在控制理論和機器人學中,這種想像一系列行動後果,然後基本上通過優化搜索滿足任務的行動序列的過程,甚至有一個名字,甚至有一個縮寫。它叫做模型預測控制(Model Predictive Control, MPC)。這是最優控制中一個非常經典的方法,可以追溯到幾十年前。 這裡的主要問題是,在機器人學和控制理論中,這種方式的運作,那個模型是一堆由某人,由工程師編寫的方程式。
我們需要為 AI 系統做的是,我們需要這個世界模型是從經驗中學習或從觀察中學習的。所以這似乎是在動物和也許是人類嬰兒的心智中發生的那種過程,通過觀察學習世界如何運作。這部分似乎真的很難複製。 現在,這可以基於一個非常簡單的原則,人們已經玩了很長時間但沒什麼成功,叫做自我監督學習(Self-supervised Learning)。而自我監督學習在自然語言理解和 LLM 等領域取得了令人難以置信的成功。事實上,它是 LLM 的基礎。
NUS120 傑出講者系列 | Yann LeCun 教授
我覺得這段最有趣。
但如果你拿一個像 Lama 4 或其他一些更新的模型,它們通常在約 30 兆個 token 上訓練,這基本上是互聯網上所有公開可用的文本。呃,一個 token 是三個位元組。 所以這通常大約是 10 的 14 次方位元組。好的,我們任何一個人讀完這些材料需要 40 萬到 50 萬年之間的時間。嗯,所以在一個生命週期內是不可能的。好的。然後將此與幾年內到達視覺皮層的資訊量進行比較。 一個年幼的孩子,一個四歲的孩子,總共清醒了 16,000 小時,而到達我們視覺皮層或透過觸覺到達我們感覺皮層的資訊量大約是每秒 2 百萬位元組。我們有兩百萬條視神經纖維從眼睛通向大腦。 每條大約攜帶每秒一個位元組。嗯,然後你做算術,你得到大約 10 的 14 次方位元組。所以在一個孩子四年的時間裡,到達視覺皮層的資訊量大約與今天最大的 LLM 消化掉的資訊量相同。所以這告訴你一些事情。 它告訴你,我們永遠無法通過在文本上訓練 LLM 來達到人類水平的 AI。這永遠不會發生。嗯,我們必須能夠從高帶寬的感官輸入(如影片或其他模態)訓練系統。嗯,壞消息是,我們目前使用的對文本效果很好的架構,對影片不起作用。 嗯,所以也許我們可以從年幼的孩子如何學習中得到一些啟發。當我說年幼的孩子時,不僅僅是人類的孩子,也包括動物。動物在生命的最初幾個小時、幾天、幾週、幾個月裡,經歷了類似的學習世界如何運作的過程。嗯,人類嬰兒需要幾個月的時間來學習關於世界非常基本的事情,比如,嗯,基本上世界是三維的。 嗯,世界上有可以獨立移動的物體,如果你因為一個物體被另一個物體擋住而看不到它,它仍然存在。這叫做物體恆存性(object permanence)。這不是我們與生俱來的。我們可能在頭兩個月學會這個。 在人類身上很難實際測量。你可以在動物身上測量。測量牠們是否真的知道物體恆存性要容易一些,這取決於物種。嗯,但還有一些事情,比如即使還不會說話的孩子,也知道一些基本的物體類別,比如狗和貓也會這樣做。 牠們自發地知道某些物體類別。牠們不需要給它們命名。嗯,然後,學習關於直覺物理學的基本概念,比如沒有支撐的物體會因為重力而掉落,這在人類身上需要九個月。在大多數動物物種中要快得多,但在人類身上需要九個月。 所以你展示底部這裡的場景,一輛小汽車停在一個平台上,然後你把那輛小汽車推下平台,它看起來漂浮在空中。一個六個月大的嬰兒不會感到驚訝。呃,一個十個月大的嬰兒會非常驚訝,因為一個十個月大的嬰兒已經學會了物體應該掉落。 所以那個十個月大的可能會看起來像那個小女孩。這實際上是心理學家測量一個嬰兒是否學會了世界的某個特定屬性的方法,就是通過測量驚訝的程度,也就是孩子盯著那個情況看多久。嗯,那麼我們如何讓機器像嬰兒一樣學習呢?嗯,事實上,這或許提出了一份未來 AI 系統的期望清單。