

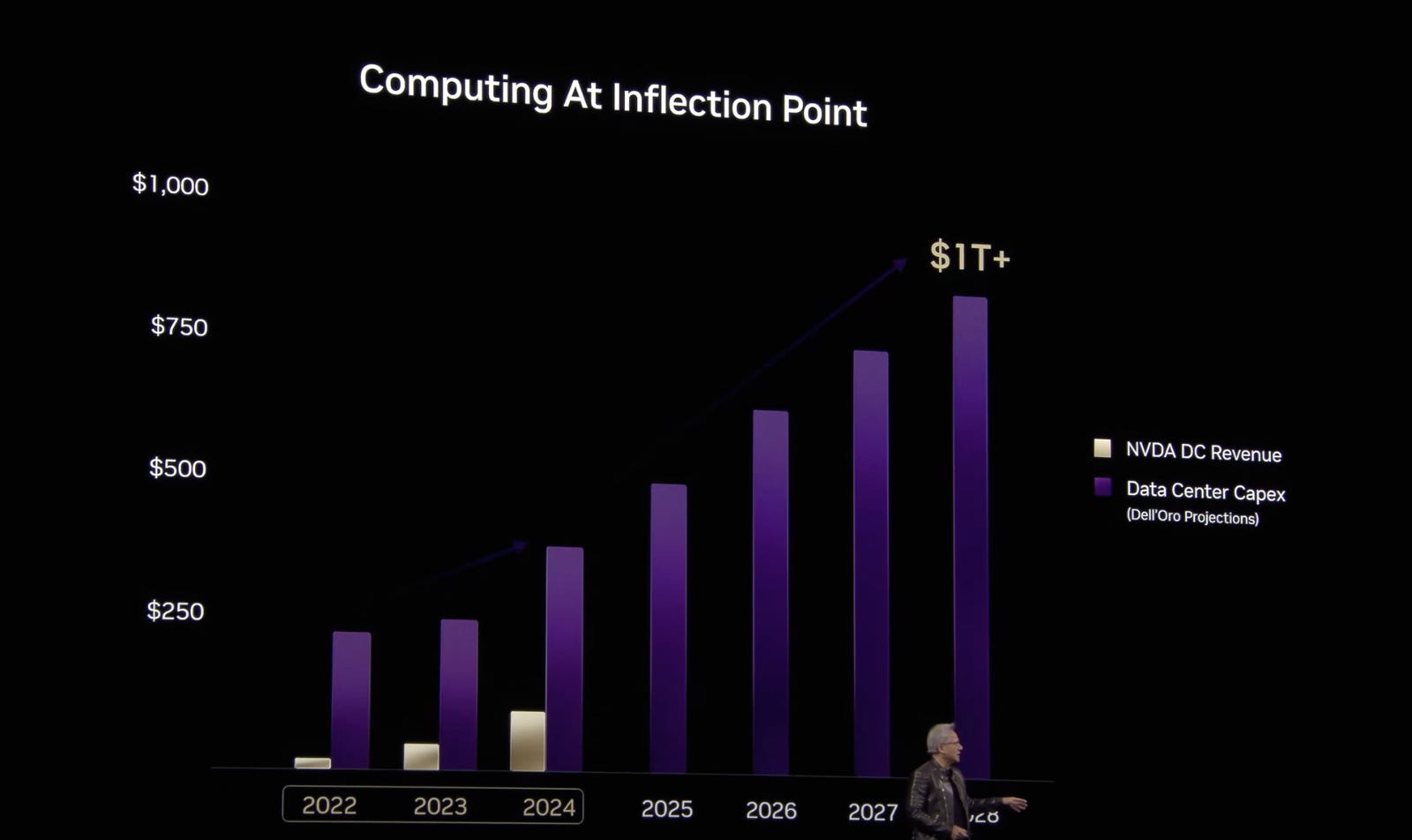
1.GPU的投資很可能是長期必須的
短期可能會有半導體週期,但隨著摩爾定律,過去的投資都是沉默成本,就像電信商每十年就被迫為了升級而替換基礎建設一樣,雲廠商必須一直購買最新的GPU以達到最好的成本效益
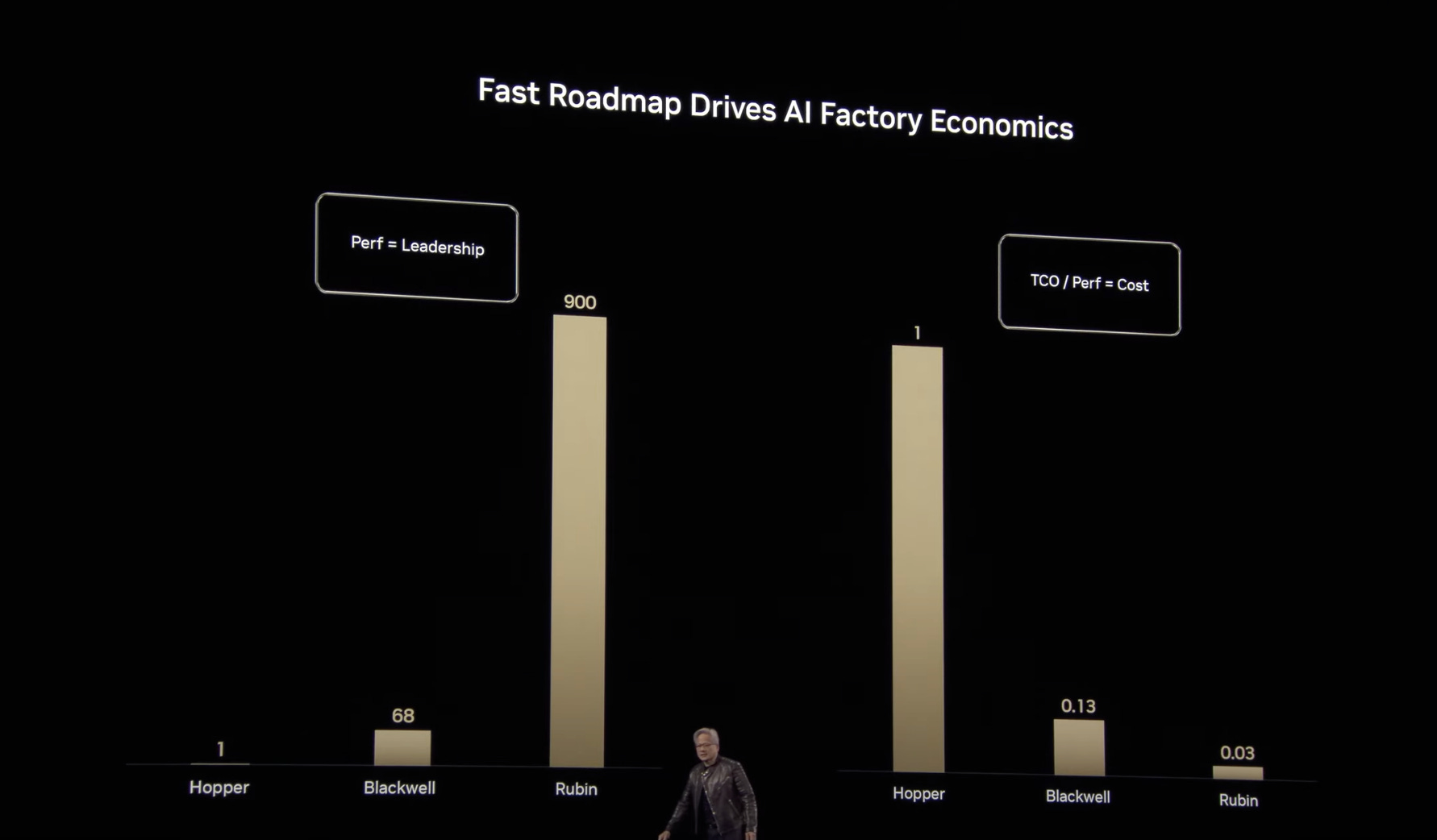
Rubin單位運算成本是hopper的3%,效能是900倍
你得一直買才有足夠的成本效益
2. 我們到達了創造性破壞的拐點了嗎?好像還沒有
Christensen 在創新的兩難一書中曾經研究到,大型硬碟雖然讀寫速度快、容量大,但非常占空間,每當小型硬碟滿足某個領域的需求之後,大型硬碟就會退出市場。
套用到AI上,雖然現在有deepseek這種便宜的模型,但是AI 應用和網路頻寬很不一樣,只要AI 能力不足,會出現幻覺,給出的資訊就沒用。
這也是為什麼大型AI還是一直往前走的原因,如果只是LLM,沒有推理,沒有多重檢查,那這個模型只是玩具,沒辦法創造可實際執行的應用(如正確處理客訴的客服、正確的翻譯、甚至是圖形與程式碼等等),所以目前顯然還在運送需求大幅增加的階段,相對LLM,推理模型其實也只是在一些領域剛好「堪用」而已,他可以解放簡單的問題,例如客服系統,有限度的軟體程式能力
從運算需求角度,推理卻需要LLM 100倍的運算量,你可以想像未來需求量還是會非常大的,目前還看不到「需求已經被既有AI過度滿足」的情形,你甚至可以說,才剛剛足夠使用在少數領域而已
3. SaaS會被破壞嗎?
如果AI停在目前的軟體程度,很難。AI 還無法很好的處理1,000行以上的程式碼,超出這個數量就會出現大量幻覺,導致系統要一直檢查。目前AI的腦容量太小,加上推理能力不足導致。
這使得企業級的軟體還暫時很難被顛覆。
軟體新手要寫一個企業級ERP,會非常痛苦,因為他需要不斷調整程式,還經常無法達到坊間SaaS的能力
但未來可能通用型SaaS會逐漸因為摩爾定律而被取代,當AI能力指數型上升時,通用型SaaS 被取代是時間的問題,這也意味著要取代SaaS 需要比現在更多的算力
4. 誰是受益者
我自己看到最終的受益者包括幾個產業:賣鏟子的人,就像這篇說的:「
在計算中,“Wintel ”時代使微軟和英特爾獲得了PC革命的大部分利潤,而不是硬盤驅動器或存儲芯片的製造商。具有諷刺意味的是,在雲計算中,Amazon AWS最初是一項基於數據中心和其他—提供的連接的OTT服務,儘管Amazon通過建立自己的數據中心而迅速垂直整合。」

第二個是資安產業,你可以想像,像我這種不會程式碼,透過AI創造程式碼的人快速上升時,很多人不知道自己在寫什麼,為駭客與病毒創造了極大的市場,資安需求會成長的非常快
第三個是擁有資料,且能夠透過AI 直接服務客戶的軟體公司(如有自己產品,且做SI 的公司,如91APP,Palantir, square等等)
軟體業的底層邏輯目前看起來不會因為LLM改變,包括網路效應、資料重力(data gravity)、規模經濟
只要擁有大量自有資料,就能透過AI去強化分析,例如91APP可以強化他的電商能力。
在此之上,還需要能夠非常理解客戶需求,只要自己真的去接觸客戶,才能是這波AI的受益者
傳統的SaaS透過四大會計事務所或顧問公司幫忙做導入,導致他們只做通用的部分,最危險,因為它們可能已經脫離,或不知道客戶需求了
例如Oracle, Salesforce 時,這些軟體的導入公司都希望我們直接採用他們的模板功能,而不是真的開發符合我們流程的產品,因為這樣他們最省事
SaaS公司們也對客製化不屑一顧
然而AI 正是打開軟體能夠具成本效益的大量客製化的關鍵,如果你長期接觸客戶,你就能快速改變自己的軟體,去適應客戶需求
我想Oracle, SAP, Salesforce 可能都已經失去這樣的能力了,或是部分失去了
近期有看到的AI相關文章
Andrew Ng吳恩達-Snowflake演講
事實上,在開發人員將代理式推理或代理式工作流程嵌入他們的應用時,我想總結出四個主要的設計模式:反思(reflection)、工具使用(tool use)、規劃(planning)、以及多代理協作(multi-agent collaboration)。當我們提示大型語言模型去檢視自己的輸出、並利用自己的評論來改進,這也可以作為多代理規劃(multi-agent planning)或多代理工作流程(multi-agent workflows)的前奏——你可以讓同一個大型語言模型在一段對話中,有時候扮演「程式開發者」角色,有時候扮演「審查者」或「批評者」的角色,審閱並給出建議。這樣在同一個對話中,透過不同角色的設定和提示,就能讓大型語言模型時而專注編寫程式碼,時而提出有建設性的批評,結果也能帶來更好的表現。所以這就是「反思(reflection)」這個設計模式。而第二個主要設計模式是「工具使用(tool use)」,在這個模式中,我們可以提示大型語言模型去生成一個 API 呼叫的請求,讓它自己決定什麼時候需要上網搜尋、執行程式碼,或者執行任務,比如發出客戶退款、發送電子郵件、或是叫出日曆條目。「工具使用」是一個主要的設計模式,它讓大型語言模型可以進行函式呼叫(function calls),我認為這擴大了我們透過這些代理式工作流程可以做到的事情。接著快速說明「規劃(planning)」或「推理(reasoning)」設計模式。在這個模式下,如果你給出一個相對複雜的請求,例如「生成一張女孩正在看書的圖片」等等,那麼,一個大型語言模型——這個範例是改編自 HuggingGPT 的論文——模型可以先檢視這個需求,決定首先要使用一個 OpenPose 模型來偵測姿勢,接著再生成一張女孩的圖片,再來描述這張圖像,最後使用 TTS(文字轉語音技術)生成音訊。因此,在「規劃」過程中,一個大型語言模型會面對一個複雜的請求,然後選擇一系列需要執行的動作,按步驟完成,來實現這個複雜任務。最後,「多代理協作(multi-agent collaboration)」則是我前面提到的設計模式。它不是僅僅提示一個大型語言模型做一件事,而是讓它在不同時間扮演不同的角色。這些模擬出來的代理彼此互動,並一起解決任務。人工智慧之父:人工智慧需要物理學才能進化 | Yann LeCun
AI拐點
楊立昆教授: 「這其實發生了兩次。第一次是在 1980 年代末期,當我們開始使用多層神經網絡(multi-layer neural networks)取得良好成果時,這在當時被稱為深度學習(deep learning),並應用於圖像識別。當時我們無法識別複雜的影像,只能處理像是手寫字符這類的簡單圖像。但即便如此,這已經是一項了不起的進步。我當時非常興奮,因為我覺得這可能會徹底改變手寫辨識技術,甚至進一步推動計算機視覺(computer vision)和 AI 發展。
然而,到了 1990 年代中期,這項技術的研究熱潮開始消退。原因是我們需要大量數據來訓練模型,而當時並沒有互聯網,因此我們只能在少數應用場景中獲取數據,例如手寫識別、字符識別和語音識別。此外,當時的計算機非常昂貴,研究投入大,因此業界對這項技術的興趣逐漸減弱。
後來,隨著 2000 年代互聯網的興起,興趣又逐漸回升,並在 2013 年迎來爆炸性成長。2013 年是 AI 研究界的關鍵轉折點,人們開始意識到深度學習的強大潛力,並將其應用到許多不同的領域。2015 年又是一個新的推進點,AI 技術的發展速度大幅加快。」楊立昆教授: 「不,我不認為現今的 AI 已經達到這種程度。目前的 AI 系統仍然非常愚蠢,我們之所以覺得它們很聰明,是因為它們擅長操控語言。然而,AI 其實並不真正理解物理世界,它們沒有我們人類擁有的那種『持久記憶(persistent memory)』,也無法真正推理和規劃。這些能力才是智慧行為(intelligent behavior)的關鍵特徵。
因此,我和我的團隊在 Meta AI(FAIR)和紐約大學(NYU)正在研究一種新型 AI 系統,它仍然基於深度學習,但我們希望它能夠理解物理世界、擁有長期記憶、具備推理與規劃能力。
在我看來,一旦我們成功打造這樣的 AI 系統,它們將會擁有類似人類的情緒,例如恐懼或興奮。」
機器學習有三種範式
第一種叫做監督式學習(supervised learning),這是最經典的一種。監督式學習系統的訓練方式是,比方說,你要訓練一個系統來辨識圖像,你會給它看一張圖片,比方說是一張桌子的照片,然後告訴它:「這是一張桌子。」這之所以叫做監督式,是因為你告訴它正確答案是什麼。系統會計算它的輸出結果,如果它說出來的結果不是「桌子」,那麼它就會調整自己的參數和內部結構,讓它的輸出結果越來越接近你希望的答案。第二種範式是增強式學習(reinforcement learning),人們認為它比較接近人類和動物的學習方式。在增強式學習中,你不會告訴系統正確答案是什麼,而只是告訴它產出的答案是好還是壞。在某種程度上,這可以解釋人類和動物的一些學習方式。例如,你試著學騎腳踏車,一開始你不會騎,結果跌倒了,你知道自己做錯了什麼,所以你會調整策略。最終,你學會怎麼騎腳踏車。第三種學習方式叫做自監督式學習(self-supervised learning),這是促成近年自然語言理解和聊天機器人進展的關鍵。在自監督式學習中,你不是訓練系統去完成某個特定任務,而是訓練它去捕捉輸入資料的內部結構。
深度學習的關鍵
關於從觀察中推演抽象表徵的問題,是深度學習的關鍵。深度學習的核心就在於學習表徵。事實上,深度學習的一個主要會議叫做國際學習表徵會議(International Conference on Learning Representations),是我與 Sheno 共同創辦的。所以,這告訴你,學習抽象表徵這個問題對於 AI 整體而言,對於深度學習特別是至關重要。現在,如果你希望系統能夠進行推理,你需要另一組特徵。基本上,推理或計劃的行為,傳統上在 AI 中,不僅僅是在基於機器學習的 AI 中,而是自 1950 年代以來,通常是尋找問題解決方案的方式。例如,如果我給你一個城市清單,並要求你給我一個最短的迴圈,經過所有這些城市,你會思考並說,嗯,我應該從附近的城市出發,這樣我的總行程就會儘可能短。現在有一個所有可能路徑的空間,也就是所有城市排列的集合,對吧?所有你可以走過的城市順序,它是一個巨大的空間,像你的 GPS 等算法搜索路徑的方式是,它們在所有可能的路徑中搜尋,找到最短的那一條。所有推理系統都基於這個搜尋的理念,在所有可能的解決方案空間中尋找一個符合你目標的解決方案。所以當前系統的運作方式就是這樣。
LLM的思考方式目前的 LLMs(像是 O1、R1,以及其他一大堆模型)在做這件事的方式其實非常非常原始。他們是在所謂的「token 空間」裡進行操作,也就是在輸出空間裡。他們基本上讓系統產生大量不同的 token 序列,呃,多多少少是隨機產生的,然後他們有另一個神經網路在檢視這些假設的序列,挑出看起來最好的那個,然後再輸出那個結果。這樣的做法極度昂貴,因為它需要產生非常大量的輸出,然後再從中挑選出好的。而且,這不是我們思考的方式。
物理AI
如果我們能夠建造出能夠理解物理世界、擁有持久記憶、可以進行推理和計劃的 AI 系統,那麼我們將擁有支持機器人的 AI 基礎,這些機器人會比現在的機器人更加靈活。
資本支出的合理性
些投資的規模大致相當,實際上並不比微軟和Meta目前所做的事情有多大區別,且大部分投資是用於推理(inference),也就是運行AI助手來服務數十億人,而不是用來訓練大型模型。訓練其實是相對便宜的。 所以我認為,金融市場的反應,比如最近幾天我們看到的反應,對於Deepseek的出現表示“現在我們可以更便宜地訓練系統,這樣我們就不需要那麼多計算機了“,這是錯誤的。訓練可能會變得更加高效,但結果是我們將訓練更大的模型,最終,大部分的基礎設施和投資是用來運行這些模型,而不是訓練它們,這才是投資的重點。
心得
假設LLM只是延續過去窮舉的道路,加上機率或向量來刪除不可能的選項,那麼未來AI應用將會停留在『幫助人類提升生產力』階段,以及提高既有流程速度
某些低階職位可以取代(如客服人員、初階工程師、設計師、UIUX),但還不到可以替代高階工作職位然而,僅僅是這樣就會創造出巨大的市場,隨著應用擴大,Token數量會指數型上升,也會帶動公有雲資本支出。Deepseek便宜的是訓練,不是運用。而更大的模型能解決更難的問題,人類即使透過LLM,也能藉由摩爾定律逐年以合理的成本,解決更難的問題。
Rubin單位運算成本是Hoper的3%,如此反覆十年以上,人類生產Token數量應該會指數型上升,因此對台積電、NVDA都是長期受益。